Searching
搜尋演算法學習筆記。
數組搜索算法
- 這些算法主要用於在排序或未排序的數組中進行搜索。
- 選擇哪種算法主要取決於數據是否排序、數據集大小、以及搜索頻率。
| 算法 | 優點 | 缺點 | 具體使用情境 |
|---|---|---|---|
| 線性搜索 Linear Search | 簡單易實現, 適用於未排序數據 | 對大型數據集效率低 | 小型數據集, 不經常搜索的場景 |
| 二分搜索 Binary Search | 效率高, 適用於排序數據 | 要求數據必須預先排序 | 大型已排序數據集, 頻繁搜索的場景 |
| 跳躍搜索 (Jump Search) | 比線性搜索快, 比二分搜索簡單 | 要求數據必須排序 | 中等大小的排序數組 |
| 插值搜索 Interpolation Search | 對於均勻分布的數據非常快 | 對於非均勻分布的數據效率低 | 大型排序且均勻分布的數值數組 |
| 指數搜索 (Exponential Search) | 適用於無界數組, 結合了二分搜索的優點 | 實現稍微複雜 | 搜索範圍未知的排序數組 |
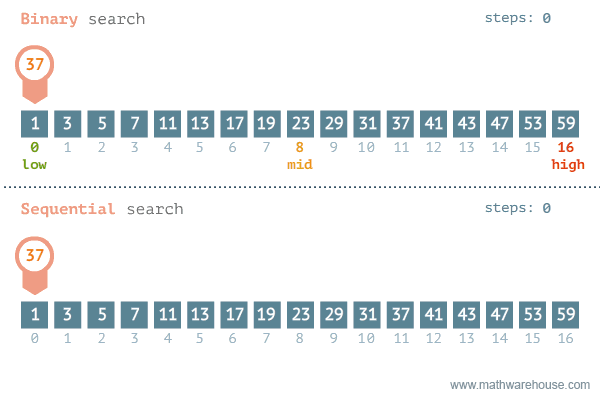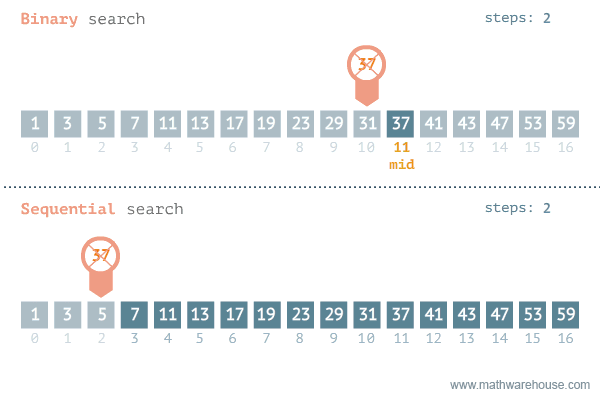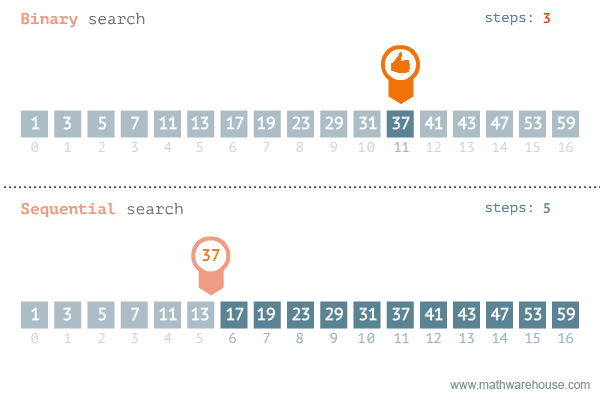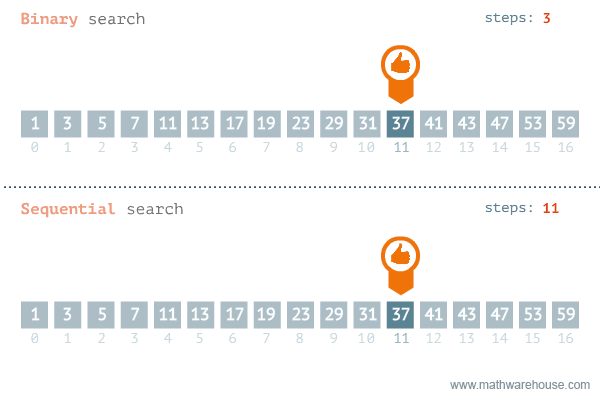
Binary Search
二分搜索 - 在已排序陣列中高效查找目標值
- Time Complexity
- Best:
- Average:
- Worst:
- Space Complexity:
- Iterative:
- Recursive:
工作原理:在排序數組中查找目標值的位置。每次比較後將搜索範圍縮減一半。
使用場景:
- 大型已排序數據集
- 需要頻繁搜索的場景
- 調試時定位錯誤發生位置
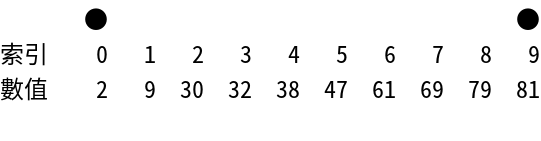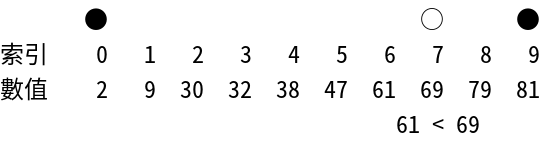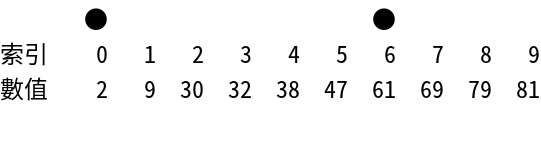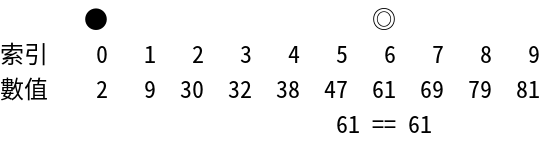
Interpolation Search
插值搜索 - 針對均勻分布數據的優化搜索算法
- Time Complexity
- Best:
- Average (均勻分布數據):
- Worst (數據呈指數增長):
- Space Complexity:
探測公式:
工作原理:改進版二分搜索,根據目標值計算探測位置。適合均勻分布的數據。
使用場景:
- 大型排序且均勻分布的數值數組
- 數據分布較為均勻時效能優於二分搜索
圖搜索算法
- 這些算法用於在圖結構(如社交網絡、地圖等)中搜索路徑或特定節點。
- 選擇取決於問題的具體需求,如是否需要最短路徑、是否有明確的目標狀態等。
| 算法 | 優點 | 缺點 | 具體使用情境 |
|---|---|---|---|
| 深度優先搜索 (DFS) | 內存效率高, 易於實現遞歸 | 可能陷入深層次的分支 | 迷宮求解, 拓撲排序, 尋找連通分量 |
| 廣度優先搜索 (BFS) | 找到最短路徑, 層次遍歷 | 內存消耗大 | 最短路徑問題, 社交網絡分析, 網頁爬蟲 |
| 貪心最佳優先搜索 (Greedy BFS) | 使用啟發式快速找到目標 | 不保證最優解 | 解決具有明確目標狀態的問題, 如八數碼問題 |
| Dijkstra算法 | 找到單源最短路徑 | 不適用於負權邊 | 導航系統, 網絡路由 |
A*搜索 (A* Search) | 結合了最佳優先搜索和啟發式方法 | 啟發函數的選擇影響效率 | 路徑規劃, 遊戲AI, 機器人導航 |
注: b為分支因子, m為最大深度, d為深度, V為頂點數, E為邊數
字符串搜索算法
- 主要用於文本處理、模式匹配等場景。
- 選擇取決於文本和模式的特性,以及是否需要處理多模式或模糊匹配。
| 算法 | 優點 | 缺點 | 具體使用情境 |
|---|---|---|---|
| KMP算法 (Knuth-Morris-Pratt) | 高效的字符串匹配 | 實現複雜, 預處理成本高 | 複雜的字符串搜索, 如文本編輯器的查找功能 |
| Rabin-Karp算法 | 可同時搜索多個模式 | 哈希函數選擇影響效率 | 多模式字符串匹配, 如抄襲檢測 |
| Boyer-Moore算法 | 在實踐中常常優於其他字符串算法 | 預處理複雜 | 大文本搜索, 如文本編輯器的查找功能 |
| 模糊搜索 (Fuzzy Search) | 能處理拼寫錯誤, 支持相似匹配 | 計算成本較高, 準確性可能不如精確匹配 | 需要容錯的搜索場景, 用戶輸入可能有誤的情況 |
注: n為文本長度, m為模式長度, k為字母表大小
概率搜索算法
- 這些算法通常用於複雜的優化問題或大規模搜索空間。
- 它們通常在傳統確定性算法效果不佳時使用。
| 算法 | 優點 | 缺點 | 具體使用情境 |
|---|---|---|---|
| 蒙特卡洛樹搜索 (MCTS) | 適用於大狀態空間, 不需要領域特定知識 | 需要大量模擬來獲得好結果 | 遊戲AI, 決策問題 |
| 模擬退火 (Simulated Annealing) | 可以逃離局部最優解 | 不保證找到全局最優解 | 組合優化問題, 如旅行商問題 |
| 遺傳算法 (Genetic Algorithm) | 可以處理複雜的優化問題 | 參數調整複雜, 收斂速度可能慢 | 複雜的優化問題, 如函數優化, 調度問題 |
注: b為分支因子, d為深度
特殊搜索算法
- 哈希搜索和布隆過濾器是兩種特殊的搜索方法,主要用於大規模數據集的快速查找和成員資格測試。
| 算法 | 優點 | 缺點 | 具體使用情境 |
|---|---|---|---|
| 哈希搜索 (Hash Search) | 利用哈希表實現近乎常數時間的查找 | 需要額外存儲空間, 可能存在哈希衝突 | 需要頻繁快速查找的大型數據集, 字典實現 |
| 布隆過濾器 (Bloom Filter) | 空間效率高, 查詢速度快 | 存在誤報可能, 不支持刪除 | 大規模數據集的成員資格測試, 緩存過濾, 網絡爬蟲URL去重 |
注: k為哈希函數數量, m為位數組大小, n為數據量