Redis Vector Database
Redis 作為向量資料庫的設定與使用方式,包含向量建模、索引建立與搜尋配置。
環境設定
使用 Python 進行向量 embedding 計算,需要以下套件:
python -m venv redisvenv
source ./redisvenv/bin/activate
pip install sentence_transformers
pip install imgbeddings首次執行時會下載 embedding 模型 all-MiniLM-L6-v2。
向量建模
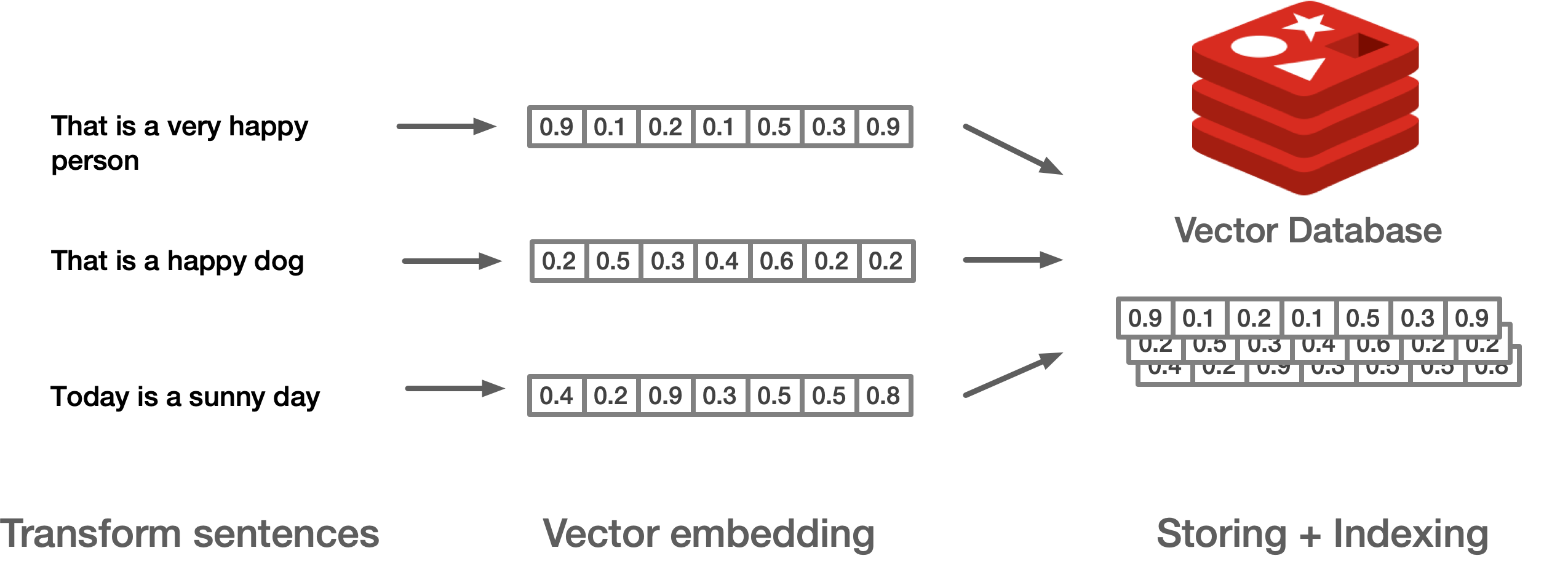
向量在 Redis 中以字串形式儲存,需要將向量序列化後存入對應的資料結構。
使用 String 儲存
最簡單的方式是直接以逗號分隔的字串儲存:
SET vec "0.00555776,0.06124274,-0.05503812,-0.08395513,-0.09052192,-0.01091553,-0.06539601,0.01099653,-0.07732834,0.0536432"使用 Hash 儲存
向量以二進位 blob 形式存於 Hash 中:
{
"content": "Understanding vector search is easy, but understanding all the mathematics behind a vector is not!",
"genre": "technical",
"embedding": "..."
}使用 JSON 儲存
透過 RedisJSON 模組,可直接以 JSON 格式儲存文件與向量。
建立向量索引
使用 FT.CREATE 指令建立向量索引,支援 Hash 與 JSON 兩種資料結構。
Hash 索引
FT.CREATE doc_idx ON HASH PREFIX 1 doc: SCHEMA content AS content TEXT genre AS genre TAG embedding VECTOR HNSW 6 TYPE FLOAT32 DIM 384 DISTANCE_METRIC COSINEJSON 索引
FT.CREATE doc_idx ON JSON PREFIX 2 doc: SCHEMA $.content AS content TEXT $.genre AS genre TAG $.embedding VECTOR HNSW 6 TYPE FLOAT32 DIM 384 DISTANCE_METRIC COSINE索引參數說明
| 參數 | 說明 | 範例值 |
|---|---|---|
DIM | 向量維度,由 embedding 模型決定 | 384(all-MiniLM-L6-v2) |
TYPE | 向量資料類型 | FLOAT32 |
DISTANCE_METRIC | 距離計算方式 | COSINE、L2、IP |
HNSW / FLAT | 索引方法 | 依資料量選擇 |
索引方法
FLAT
適合小型資料集。
- 將測試向量與索引中的所有向量逐一比較
- 結果最準確,但速度較慢且計算密集
HNSW (Hierarchical Navigable Small World)
適合大型資料集。
- 採用機率性方法,透過 HNSW 演算法進行搜尋
- 搜尋速度快,但犧牲部分準確度以換取效能提升
距離計算
餘弦距離(cosine distance)與餘弦相似度互補,可透過 1 - cosine_similarity 計算:
詳細的距離計算方式請參考 Semantic Search。
應用場景
- 文字推薦系統 - 基於文字內容的相似度推薦
- 圖片搜尋 - 透過 imgbeddings 將圖片轉換為向量
- RAG 系統 - 結合 LLM 進行檢索增強生成